将Zabbix飞书告警与本地OLLAMA大模型集成的完整技术方案:
架构拓扑
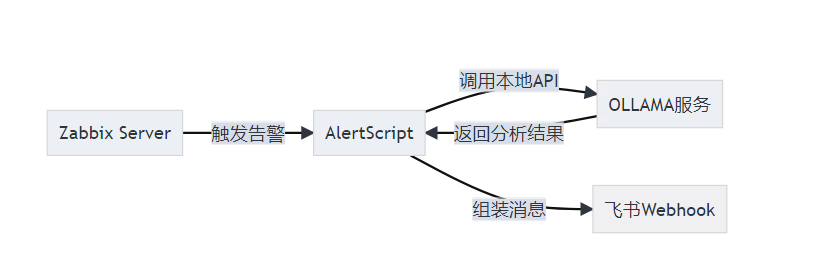
一、环境准备
1.1 系统要求
- Linux 服务器(推荐 Ubuntu 20.04+)
- Docker 与 NVIDIA 驱动(如需 GPU 加速)
- Python 3.9+(用于告警脚本)
- Zabbix Server 6.x+
- 飞书企业账号与 Webhook 地址
1.2 安装依赖
sudo apt update
sudo apt install -y docker.io python3-pip nginx
pip3 install requests diskcache prometheus_client
二、部署 OLLAMA 服务
2.1 启动容器
docker run -d --gpus=all \
-p 11434:11434 \
-v ollama:/root/.ollama \
--name ollama \
ollama/ollama
2.2 下载模型
docker exec ollama ollama pull llama3
可替换为
deepseek-r1:8b等模型。
三、配置 Nginx 网关(推荐)
3.1 配置文件
nginx
# /etc/nginx/conf.d/ollama_gateway.conf
server {
listen 11435;
server_name _;
location / {
proxy_pass http://127.0.0.1:11434;
proxy_set_header Host $host;
proxy_set_header X-Forwarded-For $remote_addr;
proxy_connect_timeout 5s;
proxy_read_timeout 15s;
proxy_send_timeout 15s;
limit_req zone=ollama burst=40 nodelay;
proxy_next_upstream error timeout http_502 http_503 http_504;
}
}
limit_req_zone $binary_remote_addr zone=ollama:10m rate=20r/s;
3.2 重启服务
sudo systemctl restart nginx
四、告警脚本配置
4.1 脚本路径
/usr/lib/zabbix/alertscripts/feishu_ollama.py
五、Zabbix 配置
5.1 媒体类型
- 类型:脚本
- 脚本:
feishu_ollama.py 参数:
代码
{ALERT.SENDTO} {ALERT.SUBJECT} {ALERT.MESSAGE}
5.2 动作模板
问题产生时
主题: {TRIGGER.NAME} 消息: 主机:{HOST.NAME} 严重度:{TRIGGER.SEVERITY} 事件ID:{EVENT.ID} 详情:{ITEM.NAME}:{ITEM.VALUE}问题恢复时
主题: {TRIGGER.NAME} 已恢复 消息: 主机:{HOST.NAME} 事件ID:{EVENT.ID} 状态:OK
六、安全加固
6.1 启用认证
docker run ... \
-e OLLAMA_AUTH="basic" \
-e OLLAMA_ORIGINS="http://zabbix-server-ip:*" \
ollama/ollama
6.2 创建用户
docker exec ollama ollama auth add --username zabbix --password StrongPass123!
6.3 脚本中添加认证
python
auth = ("zabbix", "StrongPass123!")
requests.post(..., auth=auth)
七、高可用与健康检查
7.1 多节点配置
python
OLLAMA_NODES = [
"http://ollama-node1:11434",
"http://ollama-node2:11434",
"http://ollama-node3:11434"
]
7.2 systemd 健康检查
ini
# /etc/systemd/system/ollama-health.service
[Unit]
Description=OLLAMA Health Check
After=network.target
[Service]
ExecStart=/usr/local/bin/ollama_healthcheck.sh
Restart=always
[Install]
WantedBy=multi-user.target
ollama_healthcheck.sh:
#!/bin/bash
URL="http://127.0.0.1:11434/api/tags"
if ! curl -s --max-time 2 $URL | grep -q "llama3"; then
systemctl restart ollama
fi
八、智能降级策略
- 负载过高时跳过分析
python
if os.getloadavg()[0] > 5.0:
return "🔻 系统负载过高,已跳过AI分析"
- 失败回退机制
python
try:
analysis = get_ollama_analysis(alert_message)
except Exception:
analysis = requests.get("http://backup-ai-service/analyze").text
九、验证与调试
9.1 手动测试
python3 feishu_ollama.py https://飞书webhook地址 "测试主题" "CPU负载超过90%"
9.2 查看日志
docker logs --tail 100 ollama
9.3 Prometheus 指标
ollama_analysis_durationollama_model_mem_usage
十、模型优化与定制
10.1 Modelfile 示例
dockerfile
FROM llama3
SYSTEM """
你是一个专注于运维场景的AI助手,需要:
- 使用中文输出
- 优先推荐自动化处置方案
- 对磁盘、网络、CPU问题有专业判断
"""
创建模型:
docker exec ollama ollama create myops -f Modelfile
10.2 GPU 资源隔离
docker run ... --gpus '"device=0:0"'
总结
本文覆盖了:
- 部署:OLLAMA 容器 + 模型下载
- 网关:Nginx 限流与熔断
- 脚本:增强版 Python 脚本
- Zabbix:媒体类型与动作模板
- 安全:认证与来源限制
- 高可用:多节点 + systemd 健康检查
- 降级:负载感知与回退机制
- 验证:手动测试与监控指标
- 优化:Modelfile 定制与 GPU 隔离